- Data Collection
- Introduction
- 1. Overview
-
2.
Use Cases
- 2.1. Centralized App Logging
- 2.2. Log Management & Search
- 2.3. Secure Log Forwarding
- 2.4. Log Filtering and Alerting
- 2.5. Big Data Analytics
- 2.6. Data Archiving to S3
- 2.7. Data Collection to MongoDB
- 2.8. Data Collection to HDFS
- 2.9. Data Collection to Riak
- 2.10. Windows Data Collection
- 2.11. Raspberry Pi Data Collection
- 2.12. GlusterFS Data Collection
- 2.13. Fluentd and Norikra
-
3.
Configuration
- 3.1. Configuration file
- 3.2. Common Log Formats
- 3.3. Apache Logs to Elasticsearch
- 3.4. Apache Logs to MongoDB
- 3.5. Apache Logs to S3
- 3.6. Apache Logs to Treasure Data
- 3.7. Cloudstack to MongoDB
- 3.8. CSV to Elasticsearch
- 3.9. CSV to MongoDB
- 3.10. CSV to S3
- 3.11. CSV to Treasure Data
- 3.12. HTTP to Elasticsearch
- 3.13. HTTP to MongoDB
- 3.14. HTTP to S3
- 3.15. HTTP to Treasure Data
- 3.16. Nginx to Elasticsearch
- 3.17. Nginx to MongoDB
- 3.18. Nginx to S3
- 3.19. Nginx to Treasure Data
- 3.20. Syslog to Elasticsearch
- 3.21. Syslog to MongoDB
- 3.22. Syslog to S3
- 3.23. Syslog to Treasure Data
- 3.24. TSV to S3
- 3.25. TSV to Elasticsearch
- 3.26. TSV to MongoDB
- 3.27. TSV to Treasure Data
- 3.28. JSON to Elasticsearch
- 3.29. JSON to MongoDB
- 3.30. JSON to S3
- 3.31. JSON to TreasureData
- 4. Deployment
- 5. Input Plugins
- 6. Output Plugins
- 7. Buffer Plugins
- 8. Filter Plugins
- 9. Parser Plugins
- 10. Formatter Plugins
- 11. Developer
Buffer Plugin Overview
Fluentd has 6 types of plugins: Input, Parser, Filter, Output, Formatter and Buffer. This article gives an overview of Filter Plugin.
We will first explain how Buffer Plugin works in general. Then, we will explain the mechanism of Time Sliced Plugin, a subclass of Buffer Plugin used by several core plugins.
Buffer Plugin Overview
Buffer plugins are used by buffered output plugins, such as out_file, out_forward, etc. Users can choose the buffer plugin that best suits their performance and reliability needs.
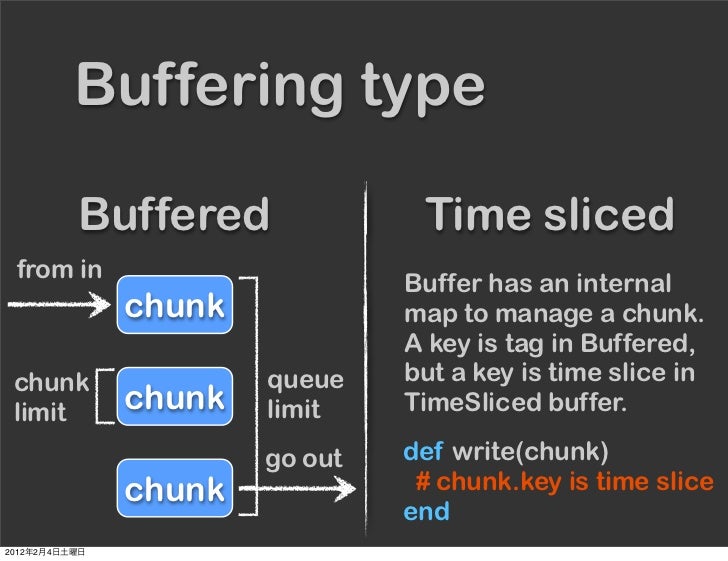
Buffer Structure
The buffer structure is a queue of chunks like the following:
queue
+---------+
| |
| chunk <-- write events to the top chunk
| |
| chunk |
| |
| chunk |
| |
| chunk --> write out the bottom chunk
| |
+---------+
When the top chunk exceeds the specified size or time limit (buffer_chunk_limit and flush_interval, respectively), a new empty chunk is pushed to the top of the queue. The bottom chunk is written out immediately when new chunk is pushed.
If the bottom chunk write out fails, it will remain in the queue and Fluentd will retry after waiting several seconds (retry_wait). If the retry limit has not been disabled (disable_retry_limit is false) and the retry count exceeds the specified limit (retry_limit), the chunk is trashed. The retry wait time doubles each time (1.0sec, 2.0sec, 4.0sec, ...). If the queue length exceeds the specified limit (buffer_queue_limit), new events are rejected.
All buffered output plugins support the following parameters:
<match pattern>
buffer_type memory
buffer_chunk_limit 256m
buffer_queue_limit 128
flush_interval 60s
disable_retry_limit false
retry_limit 17
retry_wait 1s
</match>
buffer_type specifies the buffer plugin to use. The memory Buffer plugin is used by default. You can also specify file as the buffer type alongside the buffer_path parameter as follows:
<match pattern>
buffer_type file
buffer_path /var/fluentd/buffer/ #make sure fluentd has write access to the directory!
...
</match>
The suffixes “s” (seconds), “m” (minutes), and “h” (hours) can be used for flush_interval and retry_wait. retry_wait can also be a decimal value.
The suffixes “k” (KB), “m” (MB), and “g” (GB) can be used for buffer_chunk_limit.
Time Sliced Plugin Overview
Time Sliced Plugin is a type of Buffer Plugin, so, it has the same basic buffer structure as Buffer Plugin.
In addition, each chunk is keyed by time and flushed when that chunk's timestamp has passed. This is different from This immediately raises a couple of questions.
- How do we specify the granularity of time chunks? This is done through the
time_slice_formatoption, which is set to "%Y%m%d" (daily) by default. If you want your chunks to be hourly, "%Y%m%d%H" will do the job. What if new logs come after the time corresponding the current chunk? For example, what happens to an event, timestamped at 2013-01-01 02:59:45 UTC, comes in at 2013-01-01 03:00:15 UTC? Would it make into the 2013-01-01 02:00:00-02:59:59 chunk?
This issue is addressed by setting the
time_slice_waitparameter.time_slice_waitsets, in seconds, how long fluentd waits to accept "late" events into the chunk past the max time corresponding to that chunk. The default value is 600, which means it waits for 10 minutes before moving on. So, in the current example, as long as the events come in before 2013-01-01 03:10:00, it will make it in to the 2013-01-01 02:00:00-02:59:59 chunk.Alternatively, you can also flush the chunks regularly using
flush_interval. Note thatflush_intervalandtime_slice_waitare mutually exclusive. If you setflush_interval,time_slice_waitwill be ignored and fluentd would issue a warning.
Notes
If you are curious which core output plugin use Buffered and which are Time Sliced, please see the list here